In “The Road Less Traveled: My Decision to Explore Data Science,” I wrote about my “why” of learning data science. Here I’d like to discuss where & how to get started. As a part of my data science learning journal series, this article aims to document my learning process and gather awesome resources I discovered along the way. If you’re new to the field, I hope you find them helpful.
The Venn diagram below accurately depicts the interdisciplinary nature of data science–a mixture of computer science, math/stats, and domain knowledge. It can be overwhelming for newcomers because there is so much to learn! As someone who loves systems, I found a neat framework we can follow on the data science learning journey.

In an Association for Computing Machinery (ACM) webinar, Andrew Ng (co-founder of landing.ai & Coursera, a professor at Stanford, formerly led Google Brain and Baidu’s AI team… a true AI front-runner) presented a brilliant T-shaped learning framework.
From 10+ years of teaching at Stanford, leading AI teams, and mentoring startups, Professor Ng observed that “the most skilled individuals in AI have technical portfolios that look like this”–a combination of breadth and depth:
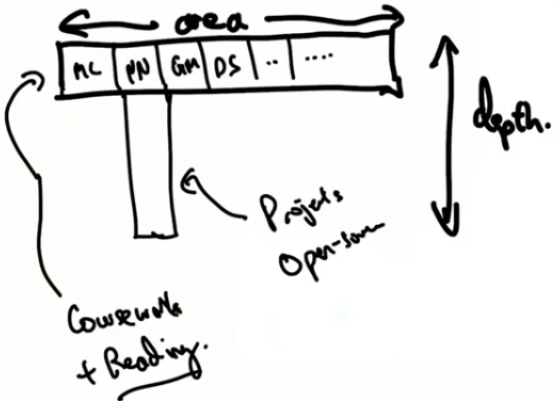
- The breadth of knowledge in many areas (e.g. machine learning, neural nets, graphical models, data science, etc.);
- The depth of knowledge in one vertical area.
1. Develop a breadth of knowledge in AI
1.1 Coursework
Taking courses is probably the most efficient way to learn AI (including data science) because most coursework has already curated and organized the knowledge in an easily digestible way.
We live in such a blessed era where knowledge is so freely accessible. Online courses have taught me so much about the data science in the past six months, both technically (coding w/ Python) and theoretically (understanding how predictive analytics works).
Here is a good catalog of courses you can get started: “Top Data Science Online Courses in 2018: A comprehensive, hand-curated list of some of the best data science courses available online.” Not on this list but highly recommended to me by many expert data scientists, the following legendary coursework will help you learn about the theories behind the most fundamental statistical and machine learning techniques in data science.
- The golden course: Machine Learning Course by Andrew Ng (Coursera)
- This Stanford machine learning course by Andrew Ng was so popular that it inspired him to start Coursera. Professor Ng did an amazing job simplifying concepts and presenting machine learning in a very approachable way.
- This is my Learning Journal on this ML course where I summarized & commented on its key points.
- It uses Octave/Matlab for exercises, so if you hope to learn Python, check out this Python implementation of the exercises.
- The golden textbook: An Introduction to Statistical Learning with Application in R (ISLR)
- This is the introductory version of the legendary textbook, The Elements of Statistical Learning, another epic intellectual product of Stanford professors!
- When you read this book, check out the video lectures by two legendary statisticians, Dr. Hastie & Dr. Tibshirani.
- The book was taught in R, so if you prefer Python like me, check out this Python implementation of its tables, figures, and labs.
1.2 Research Papers
Given the pace of technological advancement, lots of AI/machine learning knowledge has yet to be organized into coursework or textbook format. Research papers not only allow you to learn about the latest technologies, but also give you insights into areas too niche for most coursework/textbooks to cover. It’s quite inspiring to hear that Andrew, already a thought leader in the AI field, always keeps a folder of research papers in his backpack so he can read & learn whenever he has free time during the day.
Research papers sound daunting and boring to me at first, and I would never have imagined myself reading them. However, ever since I started my current data science job, I found myself diligently going through multiple research papers (mostly on insurance claim prediction). When you read research papers with a clear learning goal in mind, most are no longer dull.
Some are still dull though, especially when they are not as relevant to you. So how do you quickly pick out the good ones and efficiently read research papers? Andrew has a trick:
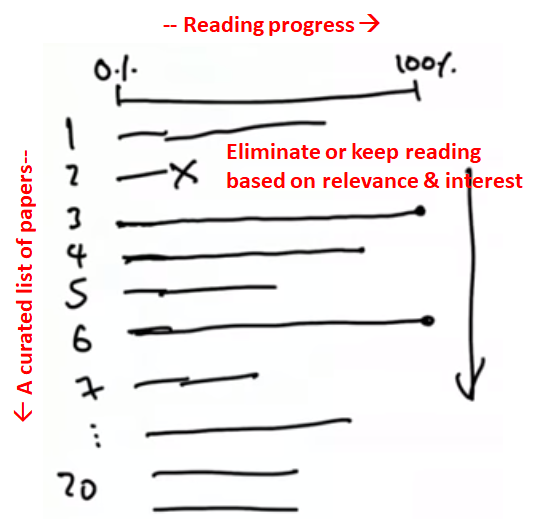
- Curate papers on the Internet and write down the list in a tracker;
- Skim all of them first, so you make a 10-15% reading progress on each paper;
- Pick out the ones that are relevant/interesting then finish reading;
- Share with colleagues & friends.
2. Develop in-depth knowledge in AI
Professor Ng believes that doing projects is the way to go! It gives you the practical, hands-on knowledge to turn theories into working models. Pick an area you like, such as machine learning, then find projects through school research opportunities, internship, work, and open source projects.
If your school/work doesn’t have any data science projects for you, don’t worry–as self-starters, we find projects for ourselves! Check out some great data science project ideas I found online:
- Advice on Building Data Portfolio Projects
- 24 Ultimate Data Science Projects To Boost Your Knowledge and Skills
Conclusion
“A journey of a thousand miles begins with a single step.” There is a lot to learn on this data science journey, but Professor Andrew Ng’s T-shaped learning framework can serve as a guiding light for all of us new to AI. To develop a breadth of knowledge: coursework is the most efficient way to learn; research papers allow you to learn about the latest technologies and niche topics. To develop a depth of knowledge, find an area to dig deep by doing projects.
If you have used materials that tremendously helped you to learn data science and/or AI, please comment below and share them with the WeZBest community, so we can learn & grow together.
Happy learning!
